If you’re interested in web technology and not yet familiar with Hugo, check it out. It’s a great way to manage and generate static websites, and it’s how I built this one. Hugo outputs a collection of static assets that require no server-side logic, so you don’t need to run a fleet of CMS webservers to build pages and respond to visitors on demand.
You can host a static site using a simple webserver, but I take this a step further by hosting my static sites in Amazon S3 and distributing them to users through Amazon CloudFront, AWS' content delivery network (CDN) service. This is especially convenient because I don’t have to worry about updates, scaling out to handle traffic spikes, or securing an admin panel. The CDN simply sends my pre-built pages to users, the same as it would with images or videos.
If you don’t already know how to use Hugo to generate a site, how to create an S3 bucket, or how to create a CloudFront distribution, I’ll refer you to their respective documentation. Get to know the basics of these three tools, then come back for tips on how to deploy your site seamlessly.
There are a couple common problems I’ve run into when delpoying static sites generated by Hugo to CloudFront and S3. If you’re using this stack, you’ll probably spend some time figuring at least one of these out. Hopefully these tips can save some of your time.
In these examples, I’m using Hugo v0.76.5. We’ll begin with a config file that looks like this — note that the value of baseURL has been updated to the domain of my CloudFront distribution:
| |
Why can’t I see my site?
I have a fresh CloudFront web distribution waiting, already configured to use my site’s S3 bucket as an origin. I’ve allowed CloudFront to create a new access identity and update the bucket’s permissions to allow the identity to read the origin bucket’s objects. All other fields are left to their default value. If I navigate to the distribution’s domain, I see S3’s dreaded 403 Forbidden response page:
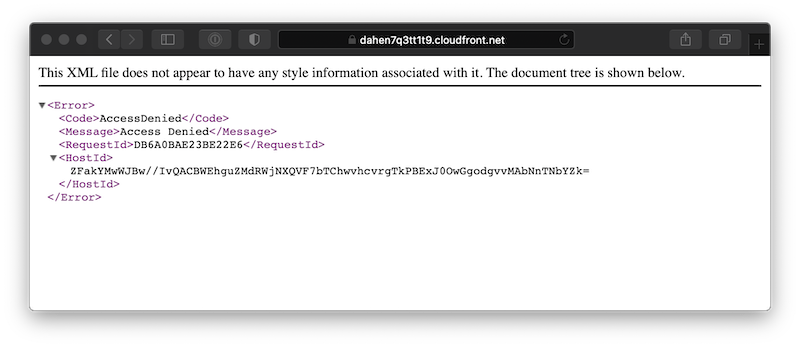
I must explicity request /index.html to view the page I expected:
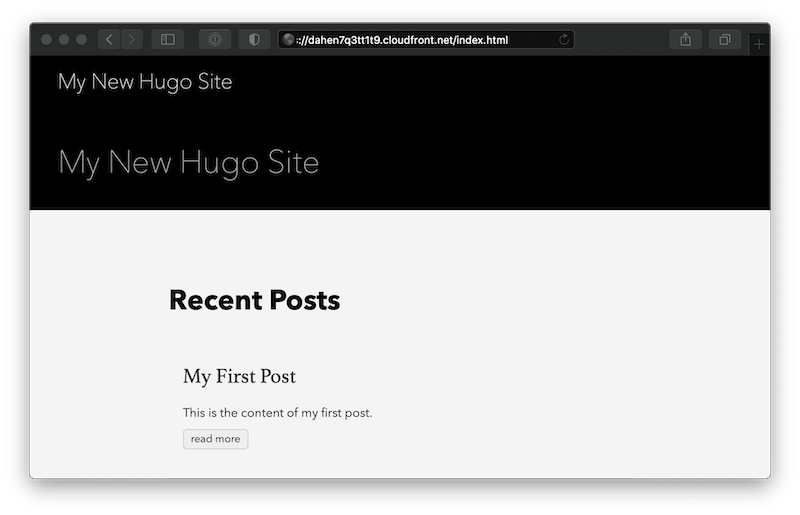
To allow a user to see your index page at the by navigating to your domain, you’ll have to let CloudFront know which object it should return by default.
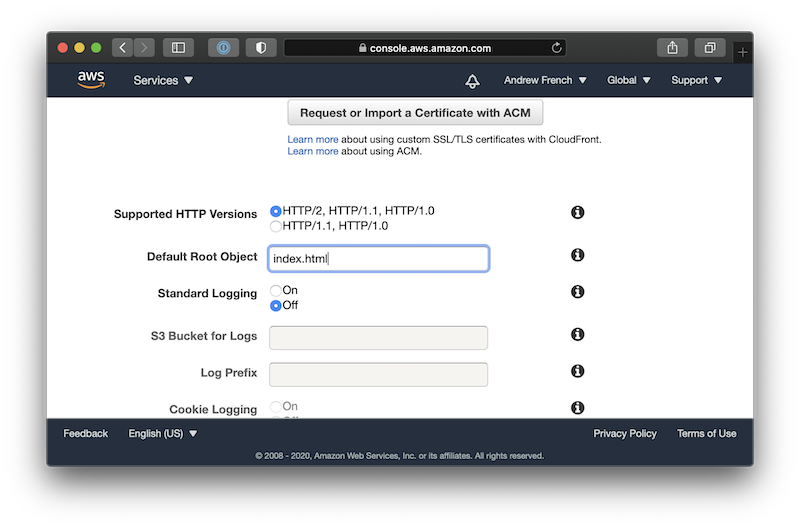
- Navigate to your CloudFront distribution
- In the General tab, click Edit
- Scroll to the Default Root Object field and enter index.html
- Click Yes, Edit
 After this change, CloudFront is configured to return the site’s index page as a default, mimicking the behavior of a traditional webserver. Users can now navigate to your domain without having to request the filename of your home page.
After this change, CloudFront is configured to return the site’s index page as a default, mimicking the behavior of a traditional webserver. Users can now navigate to your domain without having to request the filename of your home page.
Why don’t my site’s internal links work?
Now that we can see the site’s home page, we need to be able to follow links to pages. If I click the link to My First Post, I get another 403 Forbidden page. Looking at the URL, I see that the link has taken me to /posts/my-first-post/, which seems correct. Why won’t this work?
The reason for this is similar to the reason you’ll see a 403 Forbidden response when no default root object has been configured for your CloudFront distribution. Hugo generates pages in a way that leverages common behavior of most webservers, where the appropriate index.html page will be returned in response to a GET request to the bare directory. This is super common: it’s what allows you to navigate to /about/ instead of /about.html. By storing the content of your About page at /about/index.html, the webserver will infer the rest of the path, allowing the user to reference the cleaner, prettier URL.
By hosting your site’s assets on S3, you’re no longer using a traditional webserver and these convenient assumptions no longer apply. We can see this in action by editing the pretty URL to explicitly request /posts/my-first-post/index.html:
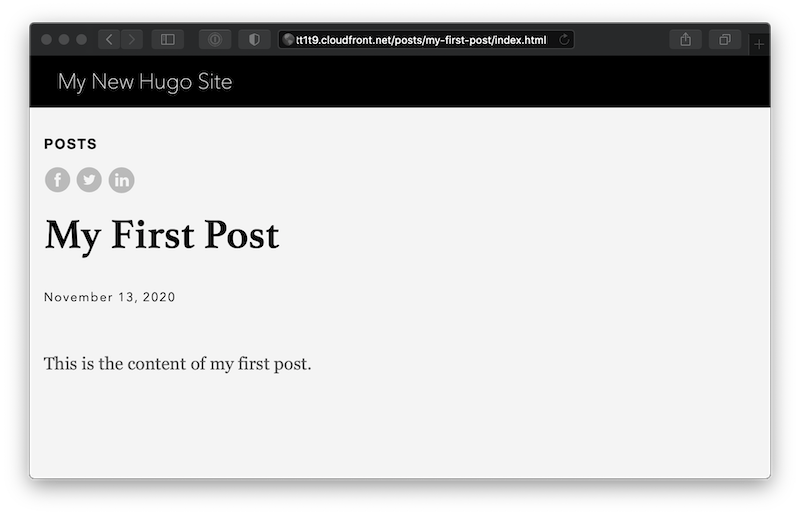
Visitors to a site can’t be expected to manually edit a URL to navigate to the page they’re looking for. We have to fix this by either configuring our infrastructure to infer the remainder of the path or by configuring Hugo to generate fully qualified links to the underlying S3 objects.
Unfortunately, we can’t configure S3 or CloudFront to return an index.html object for any path besides the root (like we did above). It is possible, however, to create a Lambda@Edge function that will perform on-the-fly rewriting of your requests, allowing you to implement this behavior on your own. I choose avoid this solution because it introduces another layer of complexity, increases latency, and increases costs (if your site has enough traffic to exceed the Lambda@Edge free tier). If this sounds like the right solution for you, check out Lambda@Edge.
Fortunately, we can enable Hugo’s uglyURLs option. When requested, Hugo writes the file that would normally be written to /about/index.html to /about.html. If a visitor will navigate your site through links, they likely won’t notice. I think this is a reasonable compromise: by choosing this solution,we give up pretty URLs but save a lot of complexity and configuration time. To enable this option, simply update your site’s config file:
| |
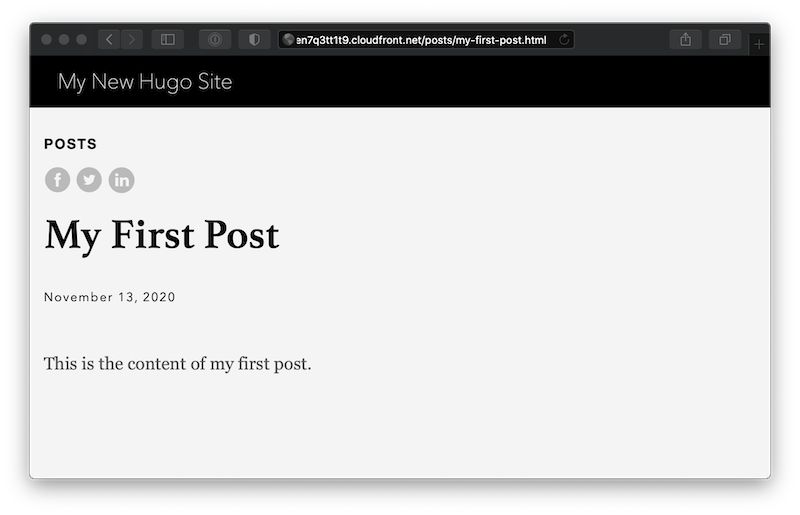
Why can’t I see my custom 404 page?
If your theme defines them, Hugo will generate custom error pages. This allows you to present your users with error pages that share the same look and feel as the rest of your site and include links back to a known page.
The 404 Not Found failure mode for a site hosted on S3 can be especially jarring. If a user has navigated to a URL that doesn’t refer to an object, they’re presented with the same unstyled 403 Forbidden page we’ve seen above.
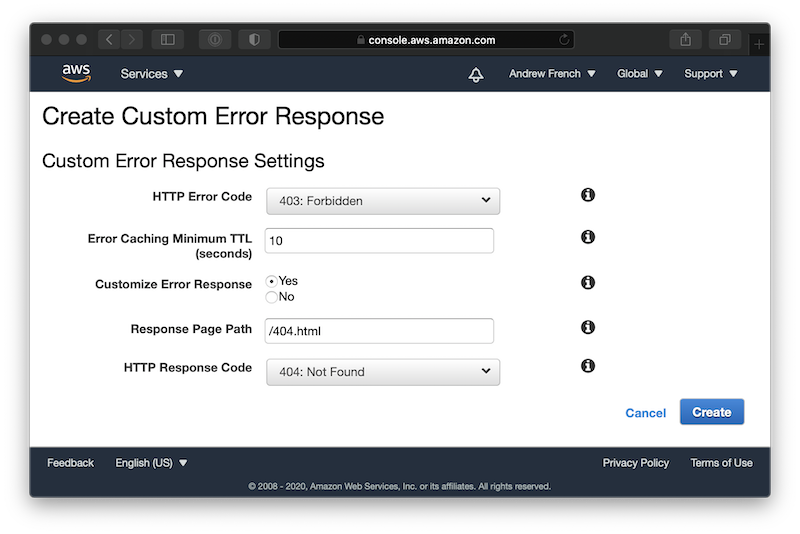
We can configure CloudFront to return an object when certain types of errors are encountered. In this case, S3’s response confuses things slightly: even though we want to return a 404 Not Found error to the client, we’re receiving a 403 Forbidden error returned by S3. Thankfully, CloudFront allows us define the response object and translate the error code passed to the client.
- Navigate to your CloudFront distribution
- In the Error Pages tab, click Create Custom Error Response
- For HTTP Error Code, select 403: Forbidden
- For Customize Error Response, select Yes
- In the Response Page Path field, enter /404.html
- For HTTP Response Code, select 404: Not Found
- Click Create
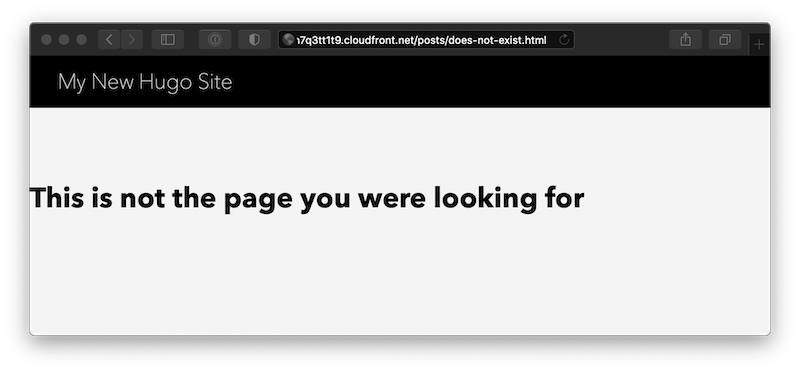
Now, we can navigate to a page we know doesn’t exist, like /posts/does-not-exist.html. We see here that the response is the custom 404.html site generated by Hugo, complete with a human-friendly message, styling that matches the site, and a link back to the home page.