A few years after I began tracking, storing, and publishing my everywhere I go, I realized I had a problem. Each time the page is loaded, the map frontend requests a file called digest.json containing a long list of coordinates representing my location history over the last four years. As I write this, it has grown to 483,714 points and weighs in at over 17 MB. The latency impact of this unweildy file has become impossible to ignore, so I’ve finally decided to do something about it.
Step One: Encoding
Currently, location data is stored and sent over the network as JSON-encoded lat-long coordinates. This is a natural and convenient way to represent a location, but it’s relatively inefficient. Here’s an example of a coordinate as it’s defined in the JSON received by the frontend:
{"lat":"37.5633","lng":"-122.3194"}
And here’s that same location encoded as a Geohash with eight-byte (±20m) precision:
9q9j8w1w
You don’t need to be a computers whiz to see the space-saving potential. By converting all the nearly half-million points from super verbose JSON-encoded lat-long coordinates to newline-delimited eight-byte Geohashes, I reduced the size of the file from 17 MB to 4.2 MB, or less than 25% of the original size. This is already a huge improvement — but I can do better.
Step Two: Deduplication
In an earlier version of the frontend, I applied a heatmap layer that made use of duplicate coordinates to highlight places I frequented with a diffuse glow. As the number of coordinates rendered on the map grew over a few hundred thousand, the performance suffered (especially on mobile). Instead of optimizing the frontend, I kicked the can down the road by simply disabling the heatmap layer. Now, points are only rendered once, so sending any duplicated points in digest.json is a waste.
Converting lat-long coordinates to Geohashes greatly increases the chance of duplicate values. While the floating-point coordinates might only be inches apart in reality, slight differences in the least significant digits make it difficult to determine groups of points that could be reasonably considered equivalent. A Geohash at any particular level of precision can be thought of as a bucket encapsulating a range of coordinates, thus limiting the number of possible values we’ll encounter. After conversion, it’s likely that several points that appeared distinct when represented as coordiante pairs will turn out to be represented by the same Geohash. By only allowing each Geohash to appear in the set once, the number of unique points drops dramatically.
After deduplicating the data set, I’m left with a 2.6 MB file containing 299,677 unique points. We’re down to just over 15% of the size of the original data set, but I can do better still.
Step Three: Compression
A Geohash is a space-filling encoding of coordinate data, which provides two important characteristics I can exploit: the first being that the precision of a Geohash is directly correlated with its length. This allows me to say, after a bit of experimentation, that an eight-byte Geohash (with precision around ±20m) is plenty for my needs. Knowing this, I can guarantee that all Geohashes encountered in this system will be exactly eight bytes long.
We already briefly discussed the second characteristic when deduplicating the set above: a Geohash can be thought of a point or a region. Any Geohash contains within its bounds all points represented by more precise Geohashes with the same prefix. For example: bcd describes a broad region that contains bcde and bcdf, which are more precise.
In practice, my location data is highly clustered. The vast majority of my time is spent around the cities in which I’ve lived. When I’m travelling, I may fly to a destination far from home, but once I arrive, I’m mostly constrained to a relatively small region. In Geohash terms, this means that many points within my data set share common prefixes.
I can exploit this characteristic to compress the data without any loss, representing the same number of Geohashes, at the same precision, without having to re-declare their prefixes dozens, hundreds, or thousands of times. Imagine a list of sorted Geohashes:

When compared to the value preceding it, each value will differ by some number of its least-significant bytes. We’ve deduplicated the data set, so we know each Geohash will differ by at least one byte. If the Geohash is wildly different, all eight bytes will differ. By highlighting just the differing values, the amount of repeated prefix information becomes apparent.

The algorithm I wrote to compress sets like this produces data indicating, for each Geohash, only which of its least-significant bytes differ from the value before it. The rest of the data (the common prefix) can be inferred from the preceding value. After removing the redundant data, we can see how each byte in the compressed data corresponds with its location in the original, uncompressed set.

By applying a windowing technique over the entire dataset in order, each compressed Geohash can be re-inflated to its original value. In my mental model, this is analogous to very simple video compression: full eight-byte values are like keyframes, a large amount of data describing an entire frame of video. These are relatively rare, because the next several frames can be efficiently described by only defining the portions of the frame that have changed from the one before it. This process can be repeated until the data has changed enough to require another keyframe, saving a huge amount of data.

The chart below illustrates how, in my personal location data, the vast majority of Geohashes inherit most of their value from their predecessors. Only in very infrequent cases (8 of 299,677, or 0.0027% of the time) will a deflated Geohash have to declare its full eight-byte value.
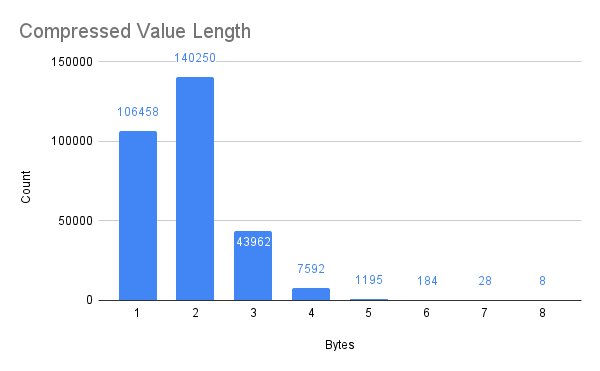
So how does this data set compare to the original? The encoded, deduplicated, and compressed data clocks in at only 836 KB, less than 5% of the size of the original! For reference, here’s a table with the results of each step:
| Points | Size (MB) | Size (%) |
|---|---|---|---|
Original | 483,714 | 17 | 100% |
Encoded | 483,714 | 4.2 | 24.7% |
Deduplicated | 299,677 | 2.6 | 15.3% |
Compressed | 299,677 | 0.856 | 4.92% |
Conclusions
Honestly, I’m pretty impressed by these results. Even when comparing only the deduplicated and the compressed Geohash sets, the compression resulted in a file only 32% the original size for a compresion ratio of 3.11!
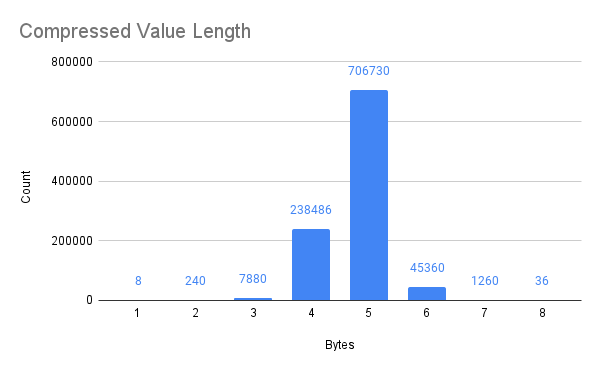
The performance of this process is highly variable depending on the data. My high compression ratio is largely due to the way a person navigates the world. To test the algorithm in general, I generated one million random Geohashes, simulating an even distribution of coordinates across the entire globe: over land, water, mountains, deserts, and everything else.
The original million Geohashes are 8.6 MB, which is reduced to 5.5 MB after compression (about 64% of the original). This corresponds to a compression ratio of 1.56. Still noticeable, but not as impressive. In the chart below, we can see that the random data typically needs to redeclare a larger portion of the eight-byte Geohash than the real-world, heavily clustered data from before. Interestingly, a huge portion of the compressed values are five bytes in length after compression.
My Geohash compression/decompression algorithm is available on Github as GHComp. Now that I’ve seen the kind of compression ratios it can achieve on real-world location data, I’ll be applying it to the map frontend as soon as possible.